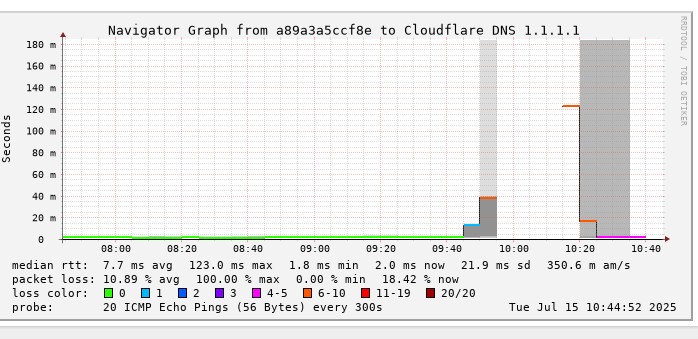
Not sure where to put this in the forums but FYI, seems Cloudflare DNS is down.


|
|

Michael Murphy | https://murfy.nz
Referral Links: Quic Broadband (use R122101E7CV7Q for free setup)
Are you happy with what you get from Geekzone? Please consider supporting us by subscribing.
Opinions are my own and not the views of my employer.










My views are as unique as a unicorn riding a unicycle. They do not reflect the opinions of my employer, my cat, or the sentient coffee machine in the break room.

|
|